



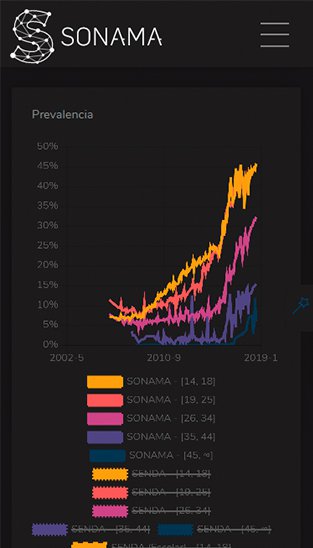
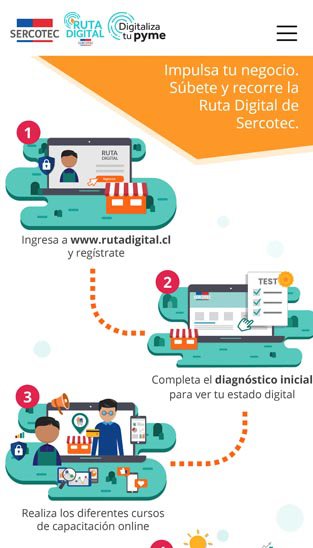

Nuestros servicios tecnológicos cuentan con una cobertura en tres áreas




Creamos tecnologías de información usando data science para apoyar la toma de decisiones en organizaciones que se interesan en innovar. Creemos que esta disciplina puede generar un gran impacto en la sociedad y eso nos apasiona.
Queremos ser un actor relevante en el área del data science y sus aplicaciones en la salud. Para ello contaremos al 2022 con al menos 3 proyectos transferidos en distintos centros de salud.


Directora Ejecutiva

Director Académico

Jefe Área Diseño

Project Manager, Data Scientist, Full-stack Developer

Project Manager

Data Scientist

Data Scientist

UX / UI Designer

Front-end Designer

Desarrolladora

Ingeniera área comercial

Data Scientist

Ingeniero de Software

Director de tecnología











